Chapter 4 – The Depletion of the IPv4 Address Space
Many people today are aware that the folks in charge of the Internet are starting to run low on addresses. Most of them are not aware that this is not the first time we’ve faced this, or just how low that pool of addresses is today. The majority of Internet users are either completely oblivious to what is going on and think that the Internet will go on like it has, forever. If they have heard any rumors about an address shortage they have a blind faith that the people in charge can simply work some magic and the problem will go away. Well, they did once, in the mid 1990’s (with NAT), but they are all out of tricks this time around. IPv4 is simply out of gas, and it is time to start using its successor, IPv6.
4.1 – OECD IPv6 Report, March 2008
The best study on this done to date (in my opinion) is in the OECD report presented at the OCED Ministerial Meeting on the Future of the Internet Economy, in Seoul Korea, 17-18 June, 2008. I was a speaker at the concurrent Korean IPv6 Summit. The full name of OECD is Organisation for Economic Co- Operation and Development. It was established in 1961, and currently has 30 member nations, including most members of the EU, plus Australia, Canada, Japan, Korea, Mexico, New Zealand, Turkey, the UK and the US. It had a 2009 budget of EUR 320 million. Their goals are to:
Unlike the IETF or ISO, the OECD is not specifically concerned with technology. However, they have determined that the imminent exhaustion of the IPv4 address space will have a major impact on most of their goal areas, hence they did a major study, the results of which are presented in Ministerial Background Report DSTI/ICCP(2007)20/FINAL, “Internet Address Space: Economic Considerations in the Management of IPv4 and in the Deployment of IPv6”. The report is available free by download over the Internet (search for “OECD IPv6 Report”). You should actually read the entire report, but I will summarize the most important aspects of it in this chapter. Let me quote one paragraph from the Main Points section:
“There is now an expectation among some experts that the currently used version of the Internet Protocol, IPv4, will run out of previously unallocated address space in 2010 or 2011, as only 16% of the total IPv4 address space remains unallocated in early 2008. The situation is critical for the future of the Internet economy because all new users connecting to the Internet, and all businesses that require IP addresses for their growth, will be affected by the change from the current status of ready availability of unallocated IPv4 addresses.”
As of this writing, in early 2010, only 8% of the addresses remain unallocated. The current best estimates are that the IANA address pool will be exhausted by July 2011, and all RIRs will exhaust their supply within six months after that (some potentially even earlier).
Another key passage from this section follows:
“As the pool of unallocated IPv4 addresses dwindles and transition to IPv6 gathers momentum, all stakeholders should anticipate the impacts of the transition period and plan accordingly. With regard to the depletion of the unallocated IPv4 address space, the most important message may be that there is no complete solution and that no option will meet all expectations. While the Internet technical community discusses optional mechanisms to manage IPv4 address space exhaustion and IPv6 deployment and to manage routing table growth pre- and post- exhaustion, governments should encourage all stakeholders to support a smooth transition to IPv6.”
“IPv6 adoption is a multi-year, complex integration process that impacts all sectors of the economy. In addition, a long period of co-existence between IPv4 and IPv6 is projected during which maintaining operations and interoperability at the application level will be critical. The fact that each player is capable of addressing only part of the issue associated with the Internet-wide transition to IPv6 underscores the need for awareness raising and co-operation”.
Basically, there is no solution for those wanting to remain with IPv4. It is going to take multiple years to make the transition. There are only two years left, so March 2010 is really the last possible date to begin a smooth and affordable introduction of IPv6. Any later start will involve unnecessary expense and crisis management, towards the end of the IPv4 lifetime. Such transitions are usually not done well when rushed. And once the addresses are gone, that’s it.
The report acknowledges that in the early phases of a major technology transition such as this, there may be little or no incentive to shift to the new technology. However, once a critical mass of users adopting the new technology, there is often a tipping point after which adoption grows rapidly until it is widespread. In theory this tipping point is reached when the marginal cost, for an ISP or an organization, of implementing the next device with IPv4 becomes higher than the cost of deploying the next device with IPv4. For an ISP, there are costs associated with deploying IPv4 nodes such as the cost of obtaining the addresses themselves, the costs of designing and deploying network infrastructure that uses fewer and fewer public (globally routable) addresses (by using NAT). When these become higher than the cost of deploying IPv6, they will begin migration in earnest. Reaching this tipping point depends on a number of factors, including customer demand, opportunity costs, emerging markets, the introduction of new services, government incentives, and regulation.
One of the key requirements for migrating to IPv6 is technical expertise in the subject. This is necessary to provide economies and companies with competitive advantage in the area of technology products and services, and the benefit from ICT-enabled innovation. Countries who are early adopters, and provide training and incentives for their companies to embrace it, or even help fund the necessary infrastructure (as in China) will have significant competitive advantages in years to come over countries that are laggards in this transition.
Increasing scarcity of IPv4 addresses can raise competitive concerns in terms of barriers to new entry and strengthening incumbent positions. There has been much discussion over how to manage previously allocated IPv4 addresses once the free pool has been exhausted. Will a black (or even a legitmate) market evolve for IPv4 addresses? Will companies that have more than they need be selling them on eBay? It’s possible that some companies might even be acquired in order to obtain a large number of addresses (as happened when Compaq bought Digital Equipment Corporation, and then again when HP bought Compaq). Today, you only borrow (lease?) addresses from an ISP for so long as you have service with that ISP. If you terminate that service, the addresses are reclaimed by the ISP for allocation to other customers. You don’t really own those addresses, so you can’t sell them. Even the ISP doesn’t own them, if an ISP goes out of business their address pool probably returns to the RIR they got them from. Some of these situations are not currently well defined, but they will be as the IPv4 address space nears exhaustion. Notably, the situation on the early Class A block allocations is not quite so well defined. Those blocks may be owned by those early adopter companies.
There is also discussion of how existing and increasing use of NAT requires developers of network aware products and applications to build increasingly complex central gateways or NAT traversal mechanisms to allow clients who are in most cases, both behind NAT gateways. This is creating barriers to innovation, the development of new services, and the overall performance and stability of the Internet.
There is a risk of some parts of the world deploying IPv6, while others continue running IPv4 with multiple layers of NAT. Such decisions would impact the economic opportunities offered by the Internet with severe repercussions in terms of stifled creativity and deployment of generally accessible new services. Also, there could be serious issues of interoperation between people in the IPv6 world and those left behind in the IPv4 world. This could lead to a fragmentation of the Internet.
The five sections of the report cover the following topics:
4.2 – OECD Follow-up Report, April 2010
In April 2010, the OECD released a follow-up report to the IPv6 report mentioned above. It is called “Internet Addressing: Measuring Deployment of IPv6”. They still expect IPv4 addresses to run out in 2012. As of March 2010, only 8% of the full IPv4 address space is available for allocation. Currently, IPv6 use is growing faster than IPv4 use, albeit from a still small base. Several large-scale deployments are taking place or are in planning. Some of the key findings, all as of March 2010 are:
Operators in the RIPE and APNIC service areas were given a survey in 2009.
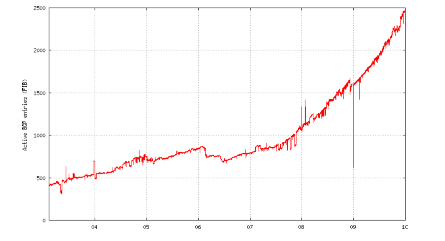
Routed IPv6 Prefixes, 2004 to 2009
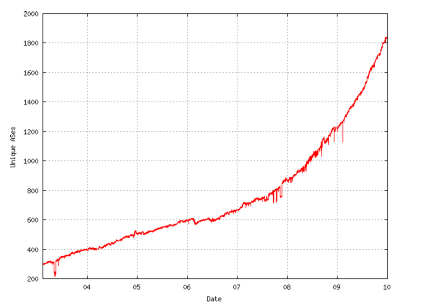
IPv6 unique Autonomous Systems, 2003 to 2009
Source: ITAC/NRO Contribution to the OECD, Geoff Huston and George Michaelson, data from end of year 2009.
Since 2008, the ratio of routed IPv6 prefixes to IPv4 prefixes has climbed from 0.45% to 0.8%, which indicates that the number of routed IPv6 prefixes is increasing more rapidly than that of routed IPv4 prefixes. The ratio of IPv6 to IPv4 AS entities actively routing went from about 3.2% in 2008 to 5.5% in 2010.
The compound annual growth rate from 24 February 2009 to 5 November 2009 for dual stack ASes was 52%, for IPv6-only ASes was 13%, and for IPv4-only ASes was 8%. At year end 2009, there were 31,582 ASes using IPv4-only, there were 1806 ASes using dual stack, and there were 59 ASes using IPv6-only.
One trend is that service providers, corporations, public agencies and end-users are using IPv6 for advanced and innovative activities on private networks. IPv6 is also being used in 6LoWPAN (IPv6 over Low power Personal Area Networks, as specified in RFC 4944, “Transmission of IPv6 Packets over IEEE 802.15.4 Networks”, September 2007.
4.3 – How IPv4 Addresses Were Allocated in the Early Days
In the early days, before IANA and the RIRs were created, IPv4 addresses were actually allocated manually by a single individual, Jon Postel. He never dreamed how large the Internet would grow, or that it would be a worldwide phenomenon that had a major impact on most world economies. He is the one responsible for allocating large chunks (“Class A” blocks) to a few early adopters (e.g. HP, Apple, and M.I.T.) Unfortunately, those allocations are very difficult to undo today, so about 1/3 of all the addresses allocated in the U.S. belong to less than 50 organizations. The IANA now just considers those legacy allocations, and has tried to do the best they could with the address space remaining at the time they took over allocation.
4.3.1 – Original “Classful” Allocation Blocks
The first 50% of the full IPv4 address space (0.0.0.0 to 127.255.255.255) was divided up into 128 “Class A” blocks (now known as “/8” or “slash-8” blocks). Each of these contained 224-2, or some 16.8 million usable addresses. Here is a list of some of the lucky organizations that own these blocks today, either from the original allocation or by buying other companies that owned them.

Another 25% of the full address space (128.0.0.0 to 191.255.255.255) was divided up into 16,384 “Class B” blocks (now known as “/16” blocks). Each of these contained 216-2, or 65,534 usable addresses.
Another 12.5% of the full address space (192.0.0.0 to 224.255.255.255) was divided up into about 2.1 million “Class C” blocks (now known as “/24” blocks). Each of these contained 28-2, or 254 usable addresses.
Another 6.25% of the full address space (224.0.0.0 to 239.255.255.255) was reserved for multicast (these are known as Class D addresses). There is no way to “recover” any of this address space.
The final 6.25% of the full address space (240.0.0.0 to 255.255.255.255) was reserved for future use, experimentation and limited broadcast. These are known as Class E addresses. These addresses cannot be “recovered” without modifications to essentially every router in the world (most routers block them by default – in many routers this is not even configurable).
The subblock of Class E from 255.0.0.0 to 255.255.255.255 is actually used for “limited broadcast” (limited because it will not cross routers). A packet sent to any of these addresses will be received by all nodes on your LAN. Of these, normally only the address 255.255.255.255 is used. There is no broadcast in IPv6 (although there is a multicast address that has much the same effect).
The U.S. Deptartment of Defense has 10 “/8” blocks, for about 168 million addresses. This is almost 4% of the total IPv4 address space. One entire “/8” block (127.x.x.x) has only one address used, which is 127.0.0.1 (the IPv4 “loopback” address, used to address your own node). A small block at 169.254.0.0/16 is reserved for IPv4 Link Local usage (similar to IPv6 link-local addresses). For details, see FC 5735, “Special Use IPv4 Addresses”, January 2010.
One “/8” block (10.0.0.0/8), one “/12” block (172.16.0.0/12) and one “/16” block (192.168.0.0/16) were reserved for use as “private” addresses by RFC 1918, “Address Allocation for Private Internets”, February 1996. These addresses can be used by any organization for any internal network, but should never be routed onto the Internet (although in practice you can sometimes find these addresses on the backbone due to misconfigured routers). These would correspond to internal phone “extensions” such as 101, 102, etc. Every company with a PBX might use that same set of extensions.
As of 4 June 2010, only 16 of the possible 256 “/8” blocks (about 6.25% of the full address space) are still unallocated. Here is a map of the status of all 256 “/8” blocks. By September 2011, (or earlier) there won’t be any dots left. All the blocks with dots (unallocated “/8”s) in the chart today will be allocated to one of the RIRs (ARIN, RIPE, APNIC, LACNIC or AfriNIC).

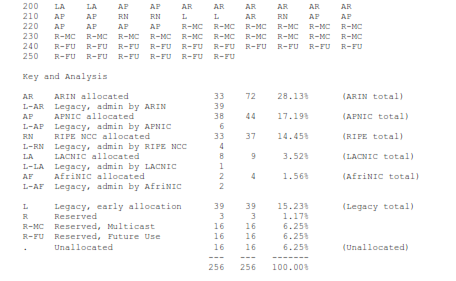
Almost all of the “Legacy, early allocation” blocks are in the U.S., so ARIN’s real share of the total IPv4 address space is over 40% (for less than 5% of the world’s population).
You can check the official status of the remaining allocations at any time, at:
http://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xml
4.3.2 – Classless Inter-Domain Routing (CIDR)
The original allocation block sizes (Classes A, B & C) did not fit all organizations. For many organizations, even the smallest block (Class C) was too big. If we had stuck with the original allocation block sizes, we would have run out of addresses around 1997. When this was realized, the IETF introduced Classless Inter-Domain Routing as defined in RFC 1518, “An Architecture for IP Address Allocation with CIDR”, September 1993; and RFC 1519 “Classless Inter-Domain Routing (CIDR): An Address Assignment and Aggregation Strategy”, September 1993. CIDR allowed allocation blocks to be split along any bit of the 32 possible bit locations, not just at 24, 16 and 8 bits. Some useful CIDR allocation block sizes are:
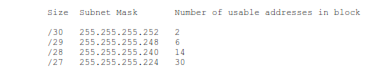
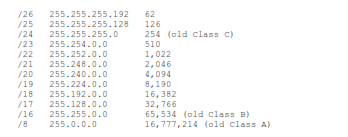
CIDR allows a closer fit to actual organization size than the old classful “3 sizes fit all” scheme. However, each allocated block requires an entry in the core routing tables. As we allocate smaller and smaller blocks, the number of entries in the core routing tables is growing very rapidly. Many things are beginning to go wrong as we get closer and closer to an empty barrel.
In the mid 1990’s, there were steps taken (NAT and Private Addresses) to further limit the number of addresses being allocated to each organization. NAT was only ever envisioned by its creators as a “quick fix” that would buy us a few years to really solve the problem. They understood all the problems NAT would cause, and were willing to live with them for a short time, when the alternative was to run out of IPv4 addresses somewhere around 1997. For the real long-term fix, the IETF also began working on the next generation Internet Protocol with a much larger address space. That next generation Internet Protocol is complete, mature and available to deploy today. It is called IPv6.
4.4 – Problems Introduced by Customer Premise Equipment NAT (CPE NAT)
Difficulty of tracking abuse to specific users behind a NAT. This requires keeping large amounts of information including source IP address, destination IP address, port number(s) and accurate time stamps for every connection. This may have to be kept for up to one year. A year’s worth of such data for a single user can be tens of gigabytes to terabytes in size. Multiplied by the number of users, this is a staggering amount of storage that ISPs are required to keep. Hackers love to “hide behind” NAT gateways.
Essentially, private IP addresses behind “hide mode” NAT are good only for outgoing connections using the simplest connectivity paradigms (e.g. client to server, using a small total number of ports per user).
It is possible to allow at most one internal node to accept incoming connections on a given port (e.g. 25 for SMTP, 80 for HTTP, etc) for a given real IPv4 address, using port forwarding. For example, your NAT gateway can be configured to forward any incoming connection to its real IPv4 address on port 25, to the private address of a single internal node where an e-mail server is running. The gateway could also forward incoming connections to its real IPv4 address on port 80 to the same or a different internal node’s private address where a web server is running. This limits the entire LAN (or that part of it behind a given real IPv4 address) to a single server for any given port number. This still translates the destination IPv4 address on the way in, and the source IPv4 address on the way out (but not port numbers), still causing many of the problems listed above.
Some firewalls (or other NAT gateways) in addition to “hide mode” (Cone) NAT for outgoing connections, and port forwarding, also support bidirectional NAT (called BINAT, symmetric NAT, and “1 to 1” NAT among other names). This type of NAT makes a two way address translation between a single real IP address and a single private internal address (hence “1 to 1”). The full 65,536 possible ports may be used on the internal node, but a distinct real IPv4 address is required for each such NAT mapping. This would allow deployment of multiple web servers within a LAN, or an easy way to provide access to many services on a single node (e.g. a Windows Server based computer). This still translates the destination IP address of packets on the way in, and the source IP address of packets on the way out (but not port numbers) still causing many of the problems listed above. In addition it uses up one real address per internal server, and requires addressing the “missing ARP” problem (caused by the fact that there is no physical node at the external address to respond to ARP queries). This can be solved by configuring a static ARP for the external IPv4 address on the NAT gateway, or various other solutions. This is one of the most difficult and least widely understood aspects of managing a NAT gateway.
There are also various NAT Traversal protocols (STUN, TURN, SOCKS, NAT-T, etc) that allow incoming connections to internal nodes that have only private addresses (without any port forwarding or BINAT support in the NAT gateway). These typically require an outside server to assist. STUN uses the outside server only to establish the connection, while TURN also routes all traffic through the outside gateway. All involve encapsulating traffic over UDP, which complicates error detection and recovery, as well as supporting the “connection oriented” nature of TCP traffic. All require extensive modifications to the source code of clients, which is quite complex and very specific to the NAT traversal algorithm used. Often the external servers used are not under control of the network, leading to security issues. One of the most popular network applications (Skype) uses standard UDP encapsulated “hole punching” traversal, which causes many security issues.
RFCs related to NAT Traversal
4.5 – Implementing NAT at the Carrier: Carrier Grade NAT (CGN) or Large Scale NAT (LSN)
As we progress from the “end times” for IPv4, to “life after IPv4” (beyond the depletion date for IPv4), those who have not already migrated to IPv6 will face even greater problems, as ISPs deploy Carrier Grade NAT or Large Scale NAT solutions in their networks, as opposed to at the Customer Premise (CPE NAT). The reason for this is to try to make optimal use of an even smaller number of real IPv4 addresses than is possible with CPE NAT. Essentially the ISP will have a very small pool of real IPv4 address (less than the number of customers). They will share single real IPv4 addresses across customers. This will make the problems associated with CPE NAT dramatically worse. There is excellent coverage of the issues associated with deploying NAT in the carrier in draft-ford-shared-addressing-issues-02 (2010-03– 08). The schemes discussed in this Internet Draft include:
Of these, only Dual-Stack Lite makes dual stack service available to users. It provides direct IPv6 service (no NAT, no tunneling). It provides IPv4 service tunneled over IPv6 with only one level of NAT44 (which takes place at the carrier). Customers will get only private IPv4 addresses. It is possible that some ISPs may provide a few precious “real” (globally routable) IPv4 addresses to business customers at a significant price premium (all the market will bear). All of the NAT schemes extend the address space by adding port information. They differ in the way they manage the port value.
With CPE NAT, a given real IPv4 address covered only one legal entity (a home, a company, etc). With carrier based NAT, multiple legal entities will be behind most real IPv4 addresses, which will vastly complicate the legal issues (such as tracking down a source of network abuse or being able to prove who really did something).
You will see the terms NAT444 and NAT464 in discussions of carrier based NAT. The existing NAT that is widely deployed now called is NAT44 (NAT from IPv4 to IPv4). There is also NAT46 (NAT from IPv4 to IPv6 and NAT64 (NAT from IPv6 to IPv4).
NAT444 essentially leaves the CPE NAT44 (the existing one layer NAT that is widely deployed today) intact at the Customer Premise, while the carrier deploys a second layer of NAT44 before it ever reaches the customer. It is really just two NAT44 mechanisms in series. The CPE NAT44 will map the pr