Chapter 7 – Transition Mechanisms
This chapter covers a variety of protocols and mechanisms that were created to simplify the introduction of IPv6 into the Internet. The goal is not to make an abrupt transition from all-IPv4 to all- IPv6 on some kind of “flag day”. That would be unbelievably disruptive, and unlikely to succeed. The goal is to gradually add new capabilities that take advantage of IPv6, or work far better over it (e.g. IPsec VPN, SIP, Mobile IP, IPTV and most other multicast), while continuing to use IPv4 for those things that work tolerably well via over IPv4 with NAT (e.g. web, email, ftp, ssh, and most client-server). This allows immediate alleviation of the most grievous problems caused by widespread deployment of NAT and other shortcomings of IPv4, while allowing a longer, more controlled migration of those protocols that do not benefit as much from IPv6. Eventually, all protocols and applications will be migrated, and IPv4 can quietly be dropped from operating systems and hardware. However, this will probably be 5 to 10 years from now. As more and more applications are transitioned to IPv6, that will take the pressure off of the remaining stock of IPv4 addresses.
Most of these transition mechanisms are defined in RFCs, and were designed as a part of the IPv6 standard. There are many mechanisms, some with confusingly similar names, such as “6in4”, “6to4”, and “6over4”, which are all quite different. Most deployments of IPv6 will use one or more of these transition mechanisms, none will use all of them. Some of the transition mechanisms are designed for use in the early phases of the transition, where there is an “ocean” of IPv4 with small (but growing) islands of IPv6 (e.g. 6in4 tunneling). Some are for use in the later stages of the transition, where the Internet has flipped into an “ocean” of IPv6, with small (and shrinking) islands of IPv4 (e.g. 4in6 tunneling).
7.1 – Relevant Standards
The following standards are relevant to IPv6 transition mechanisms:
* RFC 2473, “Generic Packet Tunneling in IPv6 Specification”, December 1998 (Standards Track) [4in6]
* RFC 2529, “Transmission of IPv6 over IPv4 Domains without Explicit Tunnels”, March 1999 (Standards Track) [6over4]
* RFC 3056, “Connection of IPv6 Domains via IPv4 Clouds”, February 2001 (Standards Track) [6to4]
* RFC 3068, “An Anycast Prefix for 6to4 Relay Routers”, June 2001 (Standards Track) *6to4+
* RFC 3964, “Security Considerations for 6to4”, December 2004 (Informational) [6to4]
* RFC 4213, “Basic Transition Mechanisms for IPv6 Hosts and Routers”, October 2005 (Standards Track) [Dual Stack, 6in4]
* RFC 4380, “Teredo: Tunneling IPv6 over UDP through Network Address Translations (NATs)”,
February 2006 (Standards Track) [Teredo]
* RFC 5158, “6to4 Reverse DNS Delegation Specification”, March 2008 (Informational) [6to4]
* RFC 5214, “Intra-Site Automatic Tunnel Addressing Protocol (ISATAP)”, March 2008 (Informational) [ISATAP]
* RFC 5569, “IPv6 Rapid Deployment on IPv4 Infrastructures (6rd)”, January 2010 (Informational) [6rd]
* RFC 5579, “Transmission of IPv4 Packets over Intra-Site Automatic Tunnel Addressing Protocol (ISATAP) Interfaces”, February 2010 (Informational)
* RFC 5571, “Softwire Hub and Spoke Deployment Framework with Layer Two Tunneling Protocol Version 2 (L2TPv2)”, June 2009 (Proposed Standard) [Softwire]
* RFC 5572, “IPv6 Tunnel Broker with the Tunnel Setup Protocol (TSP)”, February 2010 (Experimental) [TSP]
For Translation between IPv4 and IPv6, you have to go to the Internet Drafts (submitted documents that are not yet approved and given RFC numbers). This is the cutting edge of IPv6. Drafts have a lifetime of six months, and often go through many iterations before being approved (the iteration number is the last part of the draft name, e.g. -08). To keep track of them, use:
http://datatracker.ietf.org/doc/search
* draft-guo-software-6rd-ipv6-config-00, “IPv6 Host Configuration in 6rd Deployment”, 2010-13– 01
* draft-howard-isp-ip6rdns-03, “Reverse DNS in IPv6 for Internet Service Providers”, 2010-03-08
* draft-ietf-softwire-ipv6-6rd-08, “IPv6 via IPv4 Service Provider Networks ‘6rd’”, 2010-03-23
* draft-lee-softwire-6rd-udp-00, “UDP Encapsulation of 6rd”, 2009-10-18
* draft-ietf-behave-v6v4-xlate-stateful-11, “Stateful NAT64: Network Address and Protocol Translation from IPv6 Clients to IPv4 Servers”, 2010-03-30
* draft-boucadair-behave-dns64-discovery-00, “DNS64 Service Location and Discovery”, 2009-10– 18
* draft-cao-behave-dsdns64-00, “Dual Stack Hosts with DNS64”, 2010-02-12
* draft-ietf-behave-dns64-09, “DNS64: DNS extensions for Network Address Translation from Ipv6 Clients to IPv4 servers”, 2010-03-30
* draft-wing-behave-dns64-config-02, “DNS64 Resolvers and Dual-Stack Hosts”, 2010-02-12
* draft-templin-isatap-dhcp-06, “Dynamic Host Configuration Protocol (DHCPv4) Option for the Intra-Site Automatic Tunnel Addressing Protocol (ISATAP)”, 2009-12-08
* draft-ietf-softwire-dual-stack-lite-04, “Dual-Stack Lite Broadband Deployments Following IPv4 Exhaustion”, 2010-03-08
7.2 – Transition Mechanisms
There are four general classes of transition mechanisms to help us get from all-IPv4 through a mixture of IPv4 and IPv6, to eventually all-IPv6:
7.2.1 – Co-existence
Co-existence involves all client and server nodes supporting both IPv4 and IPv6 in their network stacks. The only mechanism in this group is the Dual Stack. This is the most general solution but also involves running essentially two complete networks that share the same infrastructure. It does not double network traffic, as some administrators fear. Any new connection over IPv6 is typically one less connection over IPv4. Over time, an increasing percentage of the traffic on any network will be IPv6, but the only increase in overall traffic will be from the usual suspects (increasing number of applications, users and/or customers), not from supporting Dual Stack. In fact, at some point you will see the total amount of IPv4 traffic begin to decrease. You may see an increase in incoming customer connections due to the ability to now also accept connections from IPv6 users. When YouTube started accepting connections over IPv6, there was an enormous and almost instant jump in IPv6 traffic on the backbone. Many nodes are ready to begin using IPv6 as soon as content is available, because of automated tunneling. In many cases, the end users might not even have been aware that they were now connecting over IPv6.
There is a recent variant of the dual-stack concept called Dual-Stack Lite that uses the basic dual-stack design, but adds in IP-in-IP tunneling and ISP based Network Address Translation to allow an ISP to share precious IPv4 addresses among multiple customers. It is defined in draft-ietf-softwire-dual-stack-lite-04, “Dual-Stack Lite Broadband Deployments Following IPv4 Exhaustion”.
7.2.2 – Tunneling
Tunneling involves creating IP-in-IP tunnels with a variety of mechanisms to allow sending IPv6 traffic over existing IPv4 infrastructures by adding an IPv4 packet header to the front of an entire IPv6 packet. This treats the entire IPv6 packet, including IPv6 packet header(s), TCP/UDP header and payload fields as a “black box” payload of an IPv4 packet. In the later phases of the transition, it reverses this: it treats an entire IPv4 packet, including IPv4 packet header and options, TCP/UDP header, and payload fields as a “black box” payload of an IPv6 packet. Some of these tunnel mechanisms are “automatic” (no setup required). Others require manual setup. Some require authentication while others do not. The benefit is to leverage the existing IPv4 infrastructure as a transport for IPv6 traffic, without having to wait for ISPs and equipment vendors to support IPv6 everywhere before anyone can start using it. This allows early adopters to deploy nodes and entire networks today, regardless of whether or not their ISP supports IPv6 today. In some cases (e.g. tunnels to a gateway router or firewall), when the ISP does provide dual- stack service, it is a simple process to change from tunneled service to direct service, and the process is largely transparent to inside users. There are several organizations providing free tunneled IPv6 service (using various tunnel mechanisms) during the transition, to help with the adoption of IPv6. Tunneling mechanisms include 6in4, 4in6, 6to4, 6over4, TSP (from gogonet) and Teredo. There are many Operating Systems features and installable client software available to make use of these tunneling mechanisms.
7.2.3 – Translation
This is basically Network Address Translation (with all of its attendant problems), this time between IPv4 and IPv6 (as opposed to the more traditional NAT which is IPv4 to IPv4). An IPv6 to IPv4 translation gateway allows an IPv6-only internal node to access external IPv4-only nodes and allow replies from those legacy IPv4 nodes to be returned to the originating internal IPv6 node. Connections from an internal IPv6-only node to external IPv6-only or dual-stack nodes would be done as usual over IPv6 (without going through the translation gateway). This would be useful for deploying IPv6-only nodes in a predominantly IPv4 world. An IPv4 to IPv6 gateway would allow an IPv4-only internal node to access external IPv6-only nodes, and allow replies from those external IPv6 nodes to be returned to the internal IPv4-ony node). Connections from an internal IPv4-only node to external IPv4-only nodes, or to dual-stack nodes, would be done as usual over IPv4 (without going through the translation gateway). This would be useful for deploying IPv4-only nodes in a predominantly IPv6 world. Some of these mechanisms require considerable modification to (and interaction with) DNS, such as NAT-PT and NAT64 + DNS64.
There are two broad classes of Network Address Translation between IPv4 and IPv6 – those that work at the IP layer, and are transparent to upper layers and protocols; and those that work at the application layer (i.e. Application Layer Gateways, also called Proxies). The IP layer mechanisms need only be implemented once, for all possible application layer protocols. Unfortunately they also have the most technical issues.
There are quite a few Network Address Translation mechanisms between IPv4 and IPv6 currently proposed in IETF drafts, and all have advantages and disadvantages of various kinds. None is a “clean” design without any problems. One such mechanism called NAT-PT was defined in RFC 2766, “Network Address Translation – Protocol Translation (NAT-PT)”, February 2000. It had so many issues that it has already been deprecated to historic status by RFC 4966, “Reasons to Move the Network Address Translator – Protocol Translator (NAT-PT) to Historic Status”, July 2007. Reading RFC 4966 gives a lot of insight into the issues with trying to do translation between IPv4 and IPv6 at the Internet Layer.
7.2.4 – Proxies (Application Layer Gateways)
The other kind of translation mechanism takes place at the Application Layer. They are called proxies, because they do things “on behalf of” other servers, much like a stock proxy voter will vote your stock on your behalf. They are also called Application Layer Gateways (ALGs) because they are gateways (they do forwarding of traffic from one interface to another), and they work at the Application Layer of the TCP/IP four-layer model. They don’t have the serious problems found in IP layer translation mechanisms, such as dealing with IP addresses embedded in protocols (like SIP or FTP). However, there are some problems unique to proxies:
A proxy must be written for every protocol to be translated, and often even different proxies for incoming and outgoing traffic, even for a given protocol (e.g. “SMTP in” and “SMTP out”). Typically each proxy is a considerable amount of work. Often only a handful of the most important protocol will be handled by proxies, while all other protocols are handled by packet filtering.
Writing proxies involves implementing most or all of the network protocol, although sometimes in a simplified manner (e.g. no need to store incoming e-mail messages in a way suitable for retrieval by POP3 or IMAP, just for retransmission by SMTP).
They can support SSL/TLS, but the secure connection extends only from client to proxy, and/or from proxy to server (not directly from client to server). This includes both encryption (the traffic will be “in the clear” on the proxy) and authentication (authentication is only from server to proxy, and/or proxy to client, not from server to client). Typically another digital certificate is required for the proxy server if it supports SSL/TLS (in addition to the one for the server).
They can’t work with traffic secured in the IP layer (IPsec), without access to the keys necessary to decrypt the packets.
Throughput is typically lower than with a packet filtering firewall, due to the need to process the protocol. Of course the security is much better – it won’t let through traffic that is not a valid implementation of the specific protocol, while packet filtering might let through almost anything so long as it uses the right port. There is typically no problem dealing with IP addresses embedded in a protocol.
In many cases, the proxies are not transparent, which means the client must know that it is talking not directly to a server, but via an intermediate proxy. Many protocols support this kind of operation, e.g. HTTP provides good support for an HTTP proxy. Basically, there must be a way for a client to specify not only the nodename of the final server, but also the address or nodename of the proxy server. In a browser (HTTP client), the nodename of the final server is specified as usual, and the address of the proxy server is specified during the browser configuration (“use a proxy, which is at address w.x.y.z”). When configured for proxy operation, the browser actually connects to the proxy address and relays the address of the final server to the proxy. The proxy then makes an ongoing connection to the final web server. Some protocols have no support for proxy type operation (e.g. FTP). It is possible for a firewall to recognize outgoing traffic over a given port, and automatically redirect it to a local proxy.
Application Layer Gateways (e.g. for SIP, HTTP, and SMTP) work quite well. Basically they accept a connection on one interface of a gateway, and make a second “ongoing” connection (on behalf of the original node) via another interface of the same gateway. It is easy for the two connections to use different IP versions (e.g. translate IPv4 traffic to IPv6 traffic or vice versa). In some ALGs an entire message might be spooled onto temporary storage, (e.g. email messages) and then retransmitted later. In other cases, the ongoing connection would be simultaneous with the incoming connection, and bidirectional (e.g. with HTTP). This would correspond to a human “simultaneous translator” who hears one language (e.g. Chinese), translates and simultaneously speaks another language (e.g. English).
Another example of this is an outgoing web proxy which could accept connections from either IPv4-only or IPv6-only browsers, and then make an ongoing connection to external servers using whatever version of IP those servers support (based on DNS queries). Again, this is a traditional (forward) web proxy, with the addition of IP version translation. This would allow IPv4-only or IPv6-only clients to access any external web server, regardless of IP version they support. Such a proxy could of course also provide any services normally done by an outgoing web proxy, such as caching and URL filtering.
Another example of this is a dual-stack façade that would accept incoming connections from outside over either IPv4 or IPv6, and make an ongoing connection over IPv4 to an internal IPv4-only (or over IPv6 to an IPv6-only) web server. It would relay the web server’s responses using whatever version of IP was used in the original incoming connection to the client. This is a typical “reverse” web proxy, with the addition of IP version translation. This kind of translation can help you provide dual stack versions of your web services quickly and easily, without having to dual-stack the actual servers themselves. The same technique could allow you to make your e-mail services dual stack without having to modify your existing mail server.
7.3 – Dual Stack
Dual Stack (also known as Dual IP Layer) is defined in RFC 4213, “Basic Transition Mechanisms for IPv6 Hosts and Routers”, October 2005. A dual-stack node should include code in the Internet Layer of its network stack to process both IPv4 and IPv6 packets. Typically, there is a single Link Layer that can send and receive either IPv4 or IPv6 packets. The Link Layer also contains both the IPv4 Address Resolution Protocol (ARP) and the IPv6 Neighbor Discovery (ND) protocol. The Transport Layer has only minor differences in the way IPv4 and IPv6 packets are handled, primarily concerning the way the TCP or UDP checksum is calculated (they checksum also covers the source and destination IP address from the IP header, which of course is different in the two IP versions). The application layer code can make calls to
routines in the IPv4 socket API, the IPv6 basic socket API and the IPv6 advanced socket API. IPv4 socket functions will access the IPv4 side of the IP layer, and IPv6 socket functions will access the IPv6 side of the IP layer.
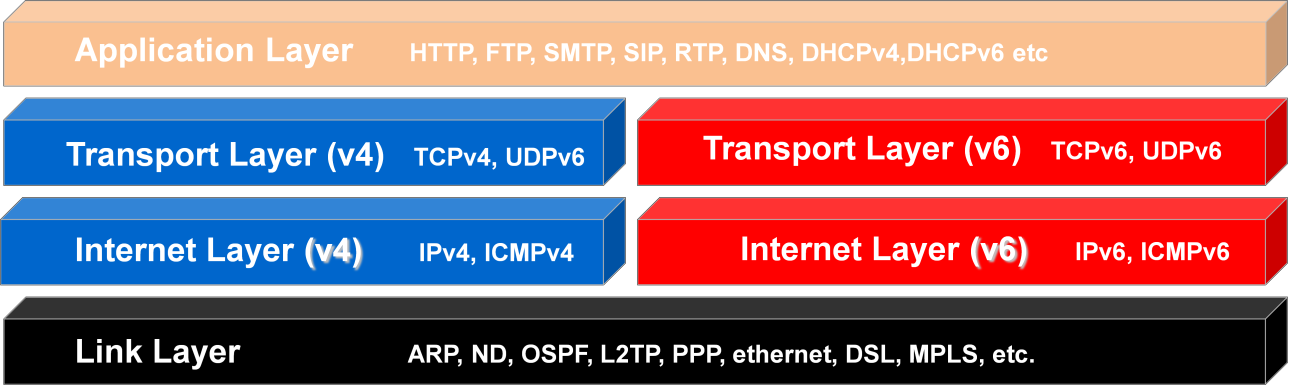
Four Layer Network Model for Dual Stack
The node should include the ability to do conventional IPv4 node configuration (including a node address, default gateway, subnet mask and addresses of DNS servers, all as 32 bit IPv4 addresses). This configuration information can be done manually, via DHCPv4, or some combination thereof. The node should also include the ability to do conventional IPv6 node configuration (including a link-local IP address, one or more global unicast address(es), a default gateway, the subnet length and the addresses of DNS servers, all 128 bit IPv6 addresses). This configuration information can be done manually, automatically via Stateless Address Autoconfiguration, automatically by DHCPv6, or by some combination thereof. There is usually a way to disable either the IPv6 functionality (in which case the node behaves as an IPv4-only node), or the IPv4 functionality (in which case the node behaves as an IPv6-only node). There may or may not also be some tunneling mechanism involved. If the node is in a native dual-stack network no tunnel mechanism is required. If the node is in an IPv4-only, or an IPv6- only network, it will require a tunnel mechanism to handle traffic of the other IP version.
IPv4-only (and for that matter, IPv6-only) applications (client, server and peer-to-peer) will work just fine on a dual-stack node. They will make calls to system functions only one side of the network stack. They will not gain any new ability to accept or make connections over the other IP version just because they are running on a dual-stack node.
A dual-stack client can connect to IPv4-only servers, IPv6-only servers, or dual-stack servers. A dual-stack server can accept connections from IPv4-only clients, IPv6-only clients, or dual-stack clients. Dual-stack is the most complete and flexible solution. The only issues are the additional complexity of implementation and deployment, and the additional memory requirements. For very small devices (typically clients), dual-stack may not be an option. Some critics of IPv6 claim that DSTM is not viable because we are running out of IPv4 addresses. What they are missing is that there are plenty of private IPv4 addresses for use behind NAT, and the IPv4 side of dual-stack systems can be used only for protocols where this is not a problem, while using their IPv6 side for those protocols which are incompatible with NAT (IPsec VPN, SIP, Mobile IP, P2P, etc), or can benefit from other IPv6 features which are superior to their IPv4 equivalents, such as multicast and QoS (SIP, IPTV, conferencing, P2P, etc). Also, any application running on that node that needs to accept a connection from external nodes (e.g. your own web server) can use a global unicast IPv6 address (for IPv6 capable clients). If you want to accept connections from IPv4 clients, you would have needed a globally routable IPv4 address for that anyway, or would need to deploy NAT Traversal (with or without dual-stack). Dual-Stack cannot create more globally routable IPv4 addresses. It can however, allow you to easily make use of an almost unlimited number of globally routable IPv6 addresses (both unicast and multicast).
A key part of a dual-stack network is a correctly configured dual-stack DNS service. It should not only be able to publish both A and AAAA records (as well as reverse PTR records for IPv4 and IPv6), it should also be able to accept queries and do zone transfers over both IPv4 and IPv6. A dual-stack network typically uses DHCPv4 to assign IPv4 addresses to each node, and either Stateless Address Autoconfiguration and/or DHCPv6 to assign IPv6 addresses to each node. A dual-stack firewall can bring in either direct dual-stack service (both IPv4 and IPv6 traffic) from an ISP (if available), routing both to the inside network; or it can bring in direct IPv4 traffic from an ISP and terminate tunneled IPv6 traffic (from a “virtual” ISP usually different from the IPv4 ISP) and route both IPv4 and IPv6 into the inside network. In either case (direct dual stack service or tunneled IPv6 with endpoint in the gateway), inside nodes appear to have direct dual-stack service, and require no support for tunneling.
The DNS support does not require any modifications to a standard DNS server (e.g. BIND). DNS just needs to be able to perform its normal forward and reverse lookups with either IPv4 (A/PTR) or IPv6 (AAAA/PTR) resource records. There is need to for the DNS server to do nonstandard mappings between IPv4 and IPv6 addresses as is required with most IP layer translation schemes (e.g. NAT64 + DNS64).
Migrating IPv4-only client or server applications to IPv6-only is quite simple. There is essentially a one to one mapping of function calls from the IPv4 socket API to similar ones in the IPv6 basic socket API. Of course, more storage is required for each IP address in data structures (4 bytes for IPv4 addresses, 16 bytes for IPv6 addresses).
Modifying either IPv4-only clients or IPv4-only servers to dual-stack operation is somewhat more complicated. A dual-stack client must be modified to retrieve multiple addresses (IPv4 and/or IPv6) from DNS, and try connections sequentially to the returned address list until a connection is accepted. The default (assuming IPv6 connectivity is available) is to attempt connections over IPv6 first. If DNS advertises an IPv6 address, and the node supports IPv6, but for some reason the client is unable to connect over IPv6 (e.g. tunnel down), there will be a 30 second timeout then a fallback to IPv4. A dual- stack server must listen for connections on either IPv4 or IPv6, and process connections from either. It is also possible to deploy two copies of each server, one being IPv4-only, and the other IPv6-only. This might involve cross process file locking on any shared resource, such as a message store. Either approach to providing dual-stack servers will work fine, and the user experience will be the same. Conditional compilation could be used to have a single source code tree create both an IPv4-only and an IPv6-only executable (depending on setting of system variables at compilation time). For most server designs (process per connection or thread per connection), the split model (an IPv4-only server and an IPv6-only server) would roughly double the memory footprint compared to a single dual-stack server.
Most open source servers today have good support for dual-stack operation. These include the Apache web server, Postfix SMTP server, Dovecot IMAP/POP3 mail access servers, etc. If you are a developer and want to see examples of how to deploy dual-stack servers, there are numerous examples available in open source. Most open source client software also has good support for IPv6 and dual-stack. These include the Firefox web browser, Thunderbird e-mail client, etc. The open source community has done an excellent job of supporting the migration to IPv6. Both the original IPv4-only socket API and the newer IPv6 socket APIs are readily available on all UNIX and UNIX-like platforms. The documentation for the newer IPv6 socket APIs are in RFC 3493, “Basic Socket Interface Extensions for IPv6” and RFC 3542, “Advanced Sockets Application Program Interface (API) for IPv6”. There is also RFC 5014, “IPv6 Socket API for Source Address Selection”, and RFC 4584, “Extension to Sockets API for Mobile IPv6”.
Virtually all Microsoft server products (since 2007) have had good support for dual-stack operation. These include Windows Server 2008 (and all of its components, such as DNS, file and printer sharing, etc); Exchange Server 2007; and many others. Their client operating systems have had good support for IPv6 since Vista. For Microsoft developers, both the original IPv4-only socket API (WinSock) and the new IPv6 socket APIs (basic and advanced) are available as part of the standard Microsoft developer libraries.
7.3.1 – Dual-Stack Lite
The IETF Softwires Working Group has come up with a variant on the basic Dual-Stack network design, which is described in draft-ietf-softwire-dual-stack-lite-04, “Dual-Stack Lite Broadband Deployments Following IPv4 Exhaustion”. Clients will still support both IPv4 and IPv6, but the service from the ISP to the customer will be IPv6-only, with IPv4 service tunneled over the IPv6. The addresses provided to the customer will be RFC 1918 private addresses, provided by a giant Large Scale NAT (LSN) at the ISP. The NAT involved actually uses the customer’s IPv6 address to tag the private IPv4 addresses used by the client, which would allow multiple ISP clients to use the same private address range (e.g. all of them could use 10.0.0.0/8, and the LSN would keep each organization’s addresses separate based on their unique IPv6 address).
IPv6-only or Dual-Stack nodes at the client would be able to connect to any IPv6 node in the world directly, via the ISPs IPv6 service. IPv4-only or Dual-Stack nodes at the client would be able to connect to any IPv4 node in the outside world via IPv4 tunneled over IPv6, with addresses from the ISP’s Large Scale NAT. There is no 6to4 translation that would allow an IPv6-only node to connect to external IPv4 nodes, or 4to6 translation that would allow an IPv4-only node to connect to external IPv6 nodes. Any internal node that needs to connect to external IPv4 nodes should be configured to support dual-stack.
The way this differs from basic Dual-Stack operation is that there is no direct IPv4 service provided, and the IPv4 addresses used at the client are private, and managed by infrastructure at the ISP. This allows the ISP to share a relatively small number of precious real IPv4 addresses among a large number of customers, and also allows the ISP to run only a single IP family of “direct service” to the customer (which happens to be IPv6). A major advantage of DS-Lite is that no 6to4 or 4to6 translation is required.
This will require a firmware upgrade (or replacement) of the Customer Premise Equipment (CPE), which is typically a DSL or cable modem, with embedded router and NAT.
This is the “IPv6 service” being trialed by Comcast in the United States as this is being written.
The ISC (who also supply the BIND DNS server and dhcpd DHCPv4 server) have created a freeware implementation of the ISP side facilities to support DS-Lite, called AFTR (Address Family Transition Router). This includes IPv4 over IPv6 tunneling, DHCPv4, DHCPv6 and some other pieces.
The CPE device for DS-Lite is called B4 (Basic Bridging BroadBand Element). There is an open source implementation of this for the Linksys WRT-54GL.
7.4 – Tunneling
If tunneled service is brought into the network by a gateway device (typically the gateway router or firewall), which contains the tunnel endpoint, the internal network is a native dual-stack network from the viewpoint of all internal nodes. No internal node needs to have support for any tunneling mechanism. If at some point, the tunneled service is replaced with direct service (both IPv4 and IPv6 service direct from your ISP) a minor reconfiguration at the gateway is all that is required. Internal nodes will probably not require any reconfiguration at all. They will typically have a new IPv6 prefix (unless you were getting tunneled service from your ISP), so you will likely have to update all forward and reverse address references in your DNS server (only for IPv6 addresses), to reflect the new IPv6 prefix. If your DNS server supports instant prefix renumbering like SolidDNS, this is a quick, painless process. If you are using DHCPv6 in stateful mode (where it assigns IP addresses) in conjunction with dynamic DNS registration, even DNS changes due to change of IPv6 prefix may happen automatically.
A tunnel mechanism has both a server side and a client side. The server side typically can accept one or more connections from tunnel clients. It is also commonly called a Tunnel Broker. A tunnel client typically makes connections to a single tunnel server. Some such connections (e.g. with 6in4) are not authenticated (although the server can typically be restricted to accepting connections only from specific IP addresses or address ranges). Some such connections (e.g. gogonet’s TSP) include authentication of the client to the server, before the tunnel will begin operation. Some connections (e.g. 6in4) require a globally routable IPv4 address on the client (although this can be the same address as the hide-mode NAT address). Other tunnel clients