3 Finding the biggest time consumers
3.1 How much is a clock cycle?
In this manual, I am using CPU clock cycles rather than seconds or microseconds as a time measure. This is because computers have very different speeds. If I write that something takes 10 μs today, then it may take only 5 μs on the next generation of computers and my manual will soon be obsolete. But if I write that something takes 10 clock cycles then it will still take 10 clock cycles even if the CPU clock frequency is doubled.
The length of a clock cycle is the reciprocal of the clock frequency. For example, if the clock frequency is 2 GHz then the length of a clock cycle is
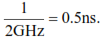
A clock cycle on one computer is not always comparable to a clock cycle on another computer. The Pentium 4 (NetBurst) CPU is designed for a higher clock frequency than other CPUs, but it uses more clock cycles than other CPUs for executing the same piece of code in general.
Assume that a loop in a program repeats 1000 times and that there are 100 floating point operations (addition, multiplication, etc.) inside the loop. If each floating point operation takes 5 clock cycles, then we can roughly estimate that the loop will take 1000 * 100 * 5 * 0.5 ns = 250 μs on a 2 GHz CPU. Should we try to optimize this loop? Certainly not! 250 μs is less than 1/50 of the time it takes to refresh the screen. There is no way the user can see the delay. But if the loop is inside another loop that also repeats 1000 times then we have an estimated calculation time of 250 ms. This delay is just long enough to be noticeable but not long enough to be annoying. We may decide to do some measurements to see if our estimate is correct or if the calculation time is actually more than 250 ms. If the response time is so long that the user actually has to wait for a result then we will consider if there is something that can be improved.
3.2 Use a profiler to find hot spots
Before you start to optimize anything, you have to identify the critical parts of the program. In some programs, more than 99% of the time is spent in the innermost loop doing mathematical calculations. In other programs, 99% of the time is spent on reading and writing data files while less than 1% goes to actually doing something on these data. It is very important to optimize the parts of the code that matters rather than the parts of the code that use only a small fraction of the total time. Optimizing less critical parts of the code will not only be a waste of time, it also makes the code less clear and more difficult to debug and maintain.
Most compiler packages include a profiler that can tell how many times each function is called and how much time it uses. There are also third-party profilers such as AQtime, Intel VTune and AMD CodeAnalyst.
There are several different profiling methods:
Unfortunately, profilers are often unreliable. They sometimes give misleading results or fail completely because of technical problems.
Some common problems with profilers are:
There are various alternatives to using a profiler. A simple alternative is to run the program in a debugger and press break while the program is running. If there is a hot spot that uses 90% of the CPU time then there is a 90% chance that the break will occur in this hot spot. Repeating the break a few times may be enough to identify a hot spot. Use the call stack in the debugger to identify the circumstances around the hot spot.
Sometimes, the best way to identify performance bottlenecks is to put measurement instruments directly into the code rather than using a ready-made profiler. This does not solve all the problems associated with profiling, but it often gives more reliable results. If you are not satisfied with the way a profiler works then you may put the desired measurement instruments into the program itself. You may add counter variables that count how many times each part of the program is executed. Furthermore, you may read the time before and after each of the most important or critical parts of the program to measure how much time each part takes. See page 154 for further discussion of this method.
Your measurement code should have #if directives around it so that it can be disabled in the final version of the code. Inserting your own profiling instruments in the code itself is a very useful way to keep track of the performance during the development of a program.
The time measurements may require a very high resolution if time intervals are short. In Windows, you can use the GetTickCount or QueryPerformanceCounter functions for millisecond resolution. A much higher resolution can be obtained with the time stamp counter in the CPU, which counts at the CPU clock frequency (in Windows: __rdtsc()).
The time stamp counter becomes invalid if a thread jumps between different CPU cores. You may have to fix the thread to a specific CPU core during time measurements to avoid this. (In Windows, SetThreadAffinityMask, in Linux, sched_setaffinity).
The program should be tested with a realistic set of test data. The test data should contain a typical degree of randomness in order to get a realistic number of cache misses and branch mispredictions.
When the most time-consuming parts of the program have been found, then it is important to focus the optimization efforts on the time consuming parts only. Critical pieces of code can be further tested and investigated by the methods described on page 154.
A profiler is most useful for finding problems that relate to CPU-intensive code. But many programs use more time loading files or accessing databases, network and other resources than doing arithmetic operations. The most common time-consumers are discussed in the following sections.
3.3 Program installation
The time it takes to install a program package is not traditionally considered a software optimization issue. But it is certainly something that can steal the user's time. The time it takes to install a software package and make it work cannot be ignored if the goal of software optimization is to save time for the user. With the high complexity of modern software, it is not unusual for the installation process to take more than an hour. Neither is it unusual that a user has to reinstall a software package several times in order to find and resolve compatibility problems.
Software developers should take installation time and compatibility problems into account when deciding whether to base a software package on a complex framework requiring many files to be installed.
The installation process should always use standardized installation tools. It should be possible to select all installation options at the start so that the rest of the installation process can proceed unattended. Uninstallation should also proceed in a standardized manner.
3.4 Automatic updates
Many software programs automatically download updates through the Internet at regular time intervals. Some programs search for updates every time the computer starts up, even if the program is never used. A computer with many such programs installed can take several minutes to start up, which is a total waste of the user's time. Other programs use time searching for updates each time the program starts. The user may not need the updates if the current version satisfies the user's needs. The search for updates should be optional and off by default unless there is a compelling security reason for updating. The update process should run in a low priority thread, and only if the program is actually used. No program should leave a background process running when it is not in use. The installation of downloaded program updates should be postponed until the program is shut down and restarted anyway.
Updates to the operating system can be particularly time consuming. Sometimes it takes hours to install automatic updates to the operating system. This is very problematic because these time consuming updates may come unpredictably at inconvenient times. This can be a very big problem if the user has to turn off or log off the computer for security reasons before leaving their workplace and the system forbids the user to turn off the computer during the update process.
3.5 Program loading
Often, it takes more time to load a program than to execute it. The load time can be annoyingly high for programs that are based on big runtime frameworks, intermediate code, interpreters, just-in-time compilers, etc., as is commonly the case with programs written in Java, C#, Visual Basic, etc.
But program loading can be a time-consumer even for programs implemented in compiled C++. This typically happens if the program uses a lot of runtime DLL's (dynamically linked libraries or shared objects), resource files, configuration files, help files and databases. The operating system may not load all the modules of a big program when the program starts up. Some modules may be loaded only when they are needed, or they may be swapped to the hard disk if the RAM size is insufficient.
The user expects immediate responses to simple actions like a key press or mouse move. It is unacceptable to the user if such a response is delayed for several seconds because it requires the loading of modules or resource files from disk. Memory-hungry applications force the operating system to swap memory to disk. Memory swapping is a frequent cause of unacceptably long response times to simple things like a mouse move or key press.
Avoid an excessive number of DLLs, configuration files, resource files, help files etc. scattered around on the hard disk. A few files, preferably in the same directory as the .exe file, is acceptable.
3.6 Dynamic linking and position-independent code
Function libraries can be implemented either as static link libraries (*.lib, *.a) or dynamic link libraries, also called shared objects (*.dll, *.so). There are several factors that can make dynamic link libraries slower than static link libraries. These factors are explained in detail on page 146 below.
Position-independent code is used in shared objects in Unix-like systems. Mac systems often use position-independent code everywhere by default. Position-independent code is inefficient, especially in 32-bit mode, for reasons explained on page 146 below.
3.7 File access
Reading or writing a file on a hard disk often takes much more time than processing the data in the file, especially if the user has a virus scanner that scans all files on access.
Sequential forward access to a file is faster than random access. Reading or writing big blocks is faster than reading or writing a small bit at a time. Do not read or write less than a few kilobytes at a time.
You may mirror the entire file in a memory buffer and read or write it in one operation rather than reading or writing small bits in a non-sequential manner.
It is usually much faster to access a file that has been accessed recently than to access it the first time. This is because the file has been copied to the disk cache.
Files on remote or removable media such as floppy disks and USB sticks may not be cached. This can have quite dramatic consequences. I once made a Windows program that created a file by calling WritePrivateProfileString, which opens and closes the file for each line written. This worked sufficiently fast on a hard disk because of disk caching, but it took several minutes to write the file to a floppy disk.
A big file containing numerical data is more compact and efficient if the data are stored in binary form than if the data are stored in ASCII form. A disadvantage of binary data storage is that it is not human readable and not easily ported to systems with big-endian storage.
Optimizing file access is more important than optimizing CPU use in programs that have many file input/output operations. It can be advantageous to put file access in a separate thread if there is other work that the processor can do while waiting for disk operations to finish.
3.8 System database
It can take several seconds to access the system database in Windows. It is more efficient to store application-specific information in a separate file than in the big registration database in the Windows system. Note that the system may store the information in the database anyway if you are using functions such as GetPrivateProfileString and WritePrivateProfileString to read and write configuration files (*.ini files).
3.9 Other databases
Many software applications use a database for storing user data. A database can consume a lot of CPU time, RAM and disk space. It may be possible to replace a database by a plain old data file in simple cases. Database queries can often be optimized by using indexes, working with sets rather than loops, etc. Optimizing database queries is beyond the scope of this manual, but you should be aware that there is often a lot to gain by optimizing database access.
3.10 Graphics
A graphical user interface can use a lot of computing resources. Typically, a specific graphics framework is used. The operating system may supply such a framework in its API. In some cases, there is an extra layer of a third-party graphics framework between the operating system API and the application software. Such an extra framework can consume a lot of extra resources.
Each graphics operation in the application software is implemented as a function call to a graphics library or API function which then calls a device driver. A call to a graphics function is time consuming because it may go through multiple layers and it needs to switch to protected mode and back again. Obviously, it is more efficient to make a single call to a graphics function that draws a whole polygon or bitmap than to draw each pixel or line separately through multiple function calls.
The calculation of graphics objects in computer games and animations is of course also time consuming, especially if there is no graphics processing unit.
Various graphics function libraries and drivers differ a lot in performance. I have no specific recommendation of which one is best.
3.11 Other system resources
Writes to a printer or other device should preferably be done in big blocks rather than a small piece at a time because each call to a driver involves the overhead of switching to protected mode and back again.
Accessing system devices and using advanced facilities of the operating system can be time consuming because it may involve the loading of several drivers, configuration files and system modules.
3.12 Network access
Some application programs use internet or intranet for automatic updates, remote help files, data base access, etc. The problem here is that access times cannot be controlled. The network access may be fast in a simple test setup but slow or completely absent in a use situation where the network is overloaded or the user is far from the server.
These problems should be taken into account when deciding whether to store help files and other resources locally or remotely. If frequent updates are necessary then it may be optimal to mirror the remote data locally.
Access to remote databases usually requires log on with a password. The log on process is known to be an annoying time consumer to many hard working software users. In some cases, the log on process may take more than a minute if the network or database is heavily loaded.
3.13 Memory access
Accessing data from RAM memory can take quite a long time compared to the time it takes to do calculations on the data. This is the reason why all modern computers have memory caches. Typically, there is a level-1 data cache of 8 - 64 Kbytes and a level-2 cache of 256 Kbytes to 2 Mbytes. There may also be a level-3 cache.
If the combined size of all data in a program is bigger than the level-2 cache and the data are scattered around in memory or accessed in a non-sequential manner then it is likely that memory access is the biggest time-consumer in the program. Reading or writing to a variable in memory takes only 2-3 clock cycles if it is cached, but several hundred clock cycles if it is not cached. See page 26 about data storage and page 87 about memory caching.
3.14 Context switches
A context switch is a switch between different tasks in a multitasking environment, between different threads in a multithreaded program, or between different parts of a big program. Frequent context switches can reduce the performance because the contents of data cache, code cache, branch target buffer, branch pattern history, etc. may have to be renewed.
Context switches are more frequent if the time slices allocated to each task or thread are smaller. The lengths of the time slices is determined by the operating system, not by the application program.
The number of context switches is smaller in a computer with multiple CPUs or a CPU with multiple cores.
3.15 Dependency chains
Modern microprocessors can do out-of-order execution. This means that if a piece of software specifies the calculation of A and then B, and the calculation of A is slow, then the microprocessor can begin the calculation of B before the calculation of A is finished. Obviously, this is only possible if the value of A is not needed for the calculation of B.
In order to take advantage of out-of-order execution, you have to avoid long dependency chains. A dependency chain is a series of calculations, where each calculation depends on the result of the preceding one. This prevents the CPU from doing mu