7 The efficiency of different C++ constructs
Most programmers have little or no idea how a piece of program code is translated into machine code and how the microprocessor handles this code. For example, many programmers do not know that double precision calculations are just as fast as single precision. And who would know that a template class is more efficient than a polymorphous class?
This chapter is aiming at explaining the relative efficiency of different C++ language elements in order to help the programmer choosing the most efficient alternative. The theoretical background is further explained in the other volumes in this series of manuals.
7.1 Different kinds of variable storage
Variables and objects are stored in different parts of the memory, depending on how they are declared in a C++ program. This has influence on the efficiency of the data cache (see page 87). Data caching is poor if data are scattered randomly around in the memory. It is therefore important to understand how variables are stored. The storage principles are the same for simple variables, arrays and objects.
Storage on the stack
Variables and objects declared inside a function are stored on the stack, except for the cases described in the sections below.
The stack is a part of memory that is organized in a first-in-last-out fashion. It is used for storing function return addresses (i.e. where the function was called from), function parameters, local variables, and for saving registers that have to be restored before the function returns. Every time a function is called, it allocates the required amount of space on the stack for all these purposes. This memory space is freed when the function returns. The next time a function is called, it can use the same space for the parameters of the new function.
The stack is the most efficient memory space to store data because the same range of memory addresses is reused again and again. If there are no big arrays, then it is almost certain that this part of the memory is mirrored in the level-1 data cache, where it is accessed quite fast.
The lesson we can learn from this is that all variables and objects should preferably be declared inside the function in which they are used.
It is possible to make the scope of a variable even smaller by declaring it inside {} brackets. However, most compilers do not free the memory used by a variable until the function returns even though it could free the memory when exiting the {} brackets in which the variable is declared. If the variable is stored in a register (see below) then it may be freed before the function returns.
Global or static storage
Variables that are declared outside of any function are called global variables. They can be accessed from any function. Global variables are stored in a static part of the memory. The static memory is also used for variables declared with the static keyword, for floating point constants, string constants, array initializer lists, switch statement jump tables, and virtual function tables.
The static data area is usually divided into three parts: one for constants that are never modified by the program, one for initialized variables that may be modified by the program, and one for uninitialized variables that may be modified by the program.
The advantage of static data is that it can be initialized to desired values before the program starts. The disadvantage is that the memory space is occupied throughout the whole program execution, even if the variable is only used in a small part of the program. This makes data caching less efficient.
Do not make variables global if you can avoid it. Global variables may be needed for communication between different threads, but that's about the only situation where they are unavoidable. It may be useful to make a variable global if it is accessed by several different functions and you want to avoid the overhead of transferring the variable as function parameter. But it may be a better solution to make the functions that access the saved variable members of the same class and store the shared variable inside the class. Which solution you prefer is a matter of programming style.
It is often preferable to make a lookup-table static. Example:
// Example 7.1
float SomeFunction (int x) {
static float list[] = {1.1, 0.3, -2.0, 4.4, 2.5};
return list[x];
}
The advantage of using static here is that the list does not need to be initialized when the function is called. The values are simply put there when the program is loaded into memory. If the word static is removed from the above example, then all five values have to be put into the list every time the function is called. This is done by copying the entire list from static memory to stack memory. Copying constant data from static memory to the stack is a waste of time in most cases, but it may be optimal in special cases where the data are used many times in a loop where almost the entire level-1 cache is used in a number of arrays that you want to keep together on the stack.
String constants and floating point constants are stored in static memory in optimized code. Example:
// Example 7.2
a = b * 3.5;
c = d + 3.5;
Here, the constant 3.5 will be stored in static memory. Most compilers will recognize that the two constants are identical so that only one constant needs to be stored. All identical constants in the entire program will be joined together in order to minimize the amount of cache space used for constants.
Integer constants are usually included as part of the instruction code. You can assume that there are no caching problems for integer constants.
Register storage
A limited number of variables can be stored in registers instead of main memory. A register is a small piece of memory inside the CPU used for temporary storage. Variables that are stored in registers are accessed very fast. All optimizing compilers will automatically choose the most often used variables in a function for register storage. The same register can be used for multiple variables as long as their uses (live ranges) do not overlap.
The number of registers is very limited. There are approximately six integer registers available for general purposes in 32-bit operating systems and fourteen integer registers in 64-bit systems.
Floating point variables use a different kind of registers. There are eight floating point registers available in 32-bit operating systems and sixteen in 64-bit operating systems. Some compilers have difficulties making floating point register variables in 32-bit mode unless the SSE2 instruction set (or higher) is enabled.
Volatile
The volatile keyword specifies that a variable can be changed by another thread. This prevents the compiler from making optimizations that rely on the assumption that the variable always has the value it was assigned previously in the code. Example:
// Example 7.3. Explain volatile
volatile int seconds; // incremented every second by another thread
void DelayFiveSeconds() {
seconds = 0;
while (seconds < 5) {
// do nothing while seconds count to 5
}
}
In this example, the DelayFiveSeconds function will wait until seconds has been incremented to 5 by another thread. If seconds was not declared volatile then an optimizing compiler would assume that seconds remains zero in the while loop because nothing inside the loop can change the value. The loop would be while (0 < 5) {} which would be an infinite loop.
The effect of the keyword volatile is that it makes sure the variable is stored in memory rather than in a register and prevents all optimizations on the variable. This can be useful in test situations to avoid that some expression is optimized away.
Note that volatile doesn't mean atomic. It doesn't prevent two threads from attempting to write the variable at the same time. The code in the above example may fail in the event that it attempts to set seconds to zero at the same time as the other thread increments seconds. A safer implementation would only read the value of seconds and wait until the value has changed five times.
Thread-local storage
Most compilers can make thread-local storage of static and global variables by using the keyword __thread or __declspec(thread). Such variables have one instance for each thread. Thread-local storage is inefficient because it is accessed through a pointer stored in a thread environment block. Thread-local storage should be avoided, if possible, and replaced by storage on the stack (see above, p. 26). Variables stored on the stack always belong to the thread in which they are created.
Far
Systems with segmented memory, such as DOS and 16-bit Windows, allow variables to be stored in a far data segment by using the keyword far (arrays can also be huge). Far storage, far pointers, and far procedures are inefficient. If a program has too much data for one segment then it is recommended to use a different operating systems that allows bigger segments (32-bit or 64-bit systems).
Dynamic memory allocation
Dynamic memory allocation is done with the operators new and delete or with the functions malloc and free. These operators and functions consume a significant amount of time. A part of memory called the heap is reserved for dynamic allocation. The heap can easily become fragmented when objects of different sizes are allocated and deallocated in random order. The heap manager can spend a lot of time cleaning up spaces that are no longer used and searching for vacant spaces. This is called garbage collection. Objects that are allocated in sequence are not necessarily stored sequentially in memory. They may be scattered around at different places when the heap has become fragmented. This makes data caching inefficient.
Dynamic memory allocation also tends to make the code more complicated and error-prone. The program has to keep pointers to all allocated objects and keep track of when they are no longer used. It is important that all allocated objects are also deallocated in all possible cases of program flow. Failure to do so is a common source of error known as memory leak. An even worse kind of error is to access an object after it has been deallocated. The program logic may need extra overhead to prevent such errors.
See page 90 for a further discussion of the advantages and drawbacks of using dynamic memory allocation.
Some programming languages, such as Java, use dynamic memory allocation for all objects. This is of course inefficient.
Variables declared inside a class
Variables declared inside a class are stored in the order in which they appear in the class declaration. The type of storage is determined where the object of the class is declared. An object of a class, structure or union can use any of the storage methods mentioned above. An object cannot be stored in a register except in the simplest cases, but its data members can be copied into registers.
A class member variable with the static modifier will be stored in static memory and will have one and only one instance. Non-static members of the same class will be stored with each instance of the class.
Storing variables in a class or structure is a good way of making sure that variables that are used in the same part of the program are also stored near each other. See page 51 for the pros and cons of using classes.
7.2 Integers variables and operators
Integer sizes
Integers can be different sizes, and they can be signed or unsigned. The following table summarizes the different integer types available.
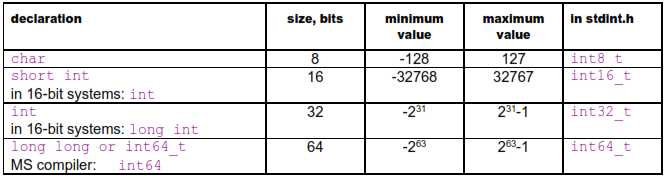
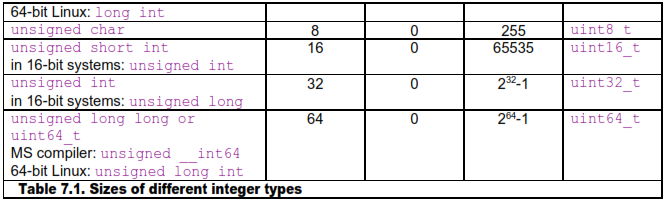
Unfortunately, the way of declaring an integer of a specific size is different for different platforms as shown in the above table. If the standard header file stdint.h or inttypes.h is available then it is recommended to use that for a portable way of defining integer types of a specific size.
Integer operations are fast in most cases, regardless of the size. However, it is inefficient to use an integer size that is larger than the largest available register size. In other words, it is inefficient to use 32-bit integers in 16-bit systems or 64-bit integers in 32-bit systems, especially if the code involves multiplication or division.
The compiler will always select the most efficient integer size if you declare an int, without specifying the size. Integers of smaller sizes (char, short int) are only slightly less efficient. In many cases, the compiler will convert these types to integers of the default size when doing calculations, and then use only the lower 8 or 16 bits of the result. You can assume that the type conversion takes zero or one clock cycle. In 64-bit systems, there is only a minimal difference between the efficiency of 32-bit integers and 64-bit integers, as long as you are not doing divisions.
It is recommended to use the default integer size in cases where the size doesn't matter and there is no risk of overflow, such as simple variables, loop counters, etc. In large arrays, it may be preferred to use the smallest integer size that is big enough for the specific purpose in order to make better use of the data cache. Bit-fields of sizes other than 8, 16, 32 and 64 bits are less efficient. In 64-bit systems, you may use 64-bit integers if the application can make use of the extra bits.
The unsigned integer type size_t is 32 bits in 32-bit systems and 64 bits in 64-bit systems. It is intended for array sizes and array indices when you want to make sure that overflow never occurs, even for arrays bigger than 2 GB.
When considering whether a particular integer size is big enough for a specific purpose, you must consider if intermediate calculations can cause overflow. For example, in the expression a = (b*c)/d, it can happen that (b*c) overflows, even if a, b, c and d would all be below the maximum value. There is no automatic check for integer overflow.
Signed versus unsigned integers
In most cases, there is no difference in speed between using signed and unsigned integers. But there are a few cases where it matters:
The conversion between signed and unsigned integers is costless. It is simply a matter of interpreting the same bits differently. A negative integer will b