Optimizing Software in C++ by Agner Fog - HTML preview
Download the book in PDF, ePub, Kindle for a complete version.
13 Making critical code in multiple versions for different instruction sets
Microprocessor producers keep adding new instructions to the instruction set. These new instructions can make certain kinds of code execute faster. The most important addition to the instruction set is the vector operations mentioned in chapter 12.
If the code is compiled for a particular instruction set then it will be compatible with all CPUs that support this instruction set or any higher instruction set, but possibly not with earlier CPUs. The sequence of backwards compatible instruction sets is as follows:
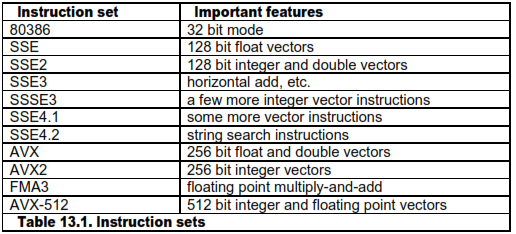
A more detailed explanation of the instruction sets is provided in manual 4: "Instruction tables". There are certain restrictions on mixing code compiled for AVX or later with code compiled without AVX, as explained on page 107.
A disadvantage of using the newest instruction set is that the compatibility with older microprocessors is lost. This dilemma can be solved by making the most critical parts of the code in multiple versions for different CPUs. This is called CPU dispatching. For example, you may want to make one version that takes advantage of the AVX2 instruction set, another version for CPUs with only the SSE2 instruction set, and a generic version that is compatible with old microprocessors without any of these instruction sets. The program should automatically detect which instruction set is supported by the CPU and the operating system and choose the appropriate version of the subroutine for the critical innermost loops.
13.1 CPU dispatch strategies
It is quite expensive - in terms of development, testing and maintenance - to make a piece of code in multiple versions, each carefully optimized and fine-tuned for a particular set of CPUs. These costs can be justified for general function libraries that are used in multiple applications, but not always for application-specific code. If you consider making highly optimized code with CPU dispatching, then it is advisable to make it in the form of a re- usable library if possible. This also makes testing and maintenance easier.
I have done a good deal of research on CPU dispatching and discovered that many common programs use inappropriate CPU dispatch methods.
The most common pitfalls of CPU dispatching are:
- Optimizing for present processors rather than future processors. Consider the time it takes to develop and publish a function library with CPU dispatching. Add to this the time it takes before the application programmer gets the new version of the library. Add to this the time it takes to develop and market the application program. Add to this the time before the end user gets the latest version of the application program. All in all, it will often take several years before your code is running in the majority of end user's computers. At this time, any processor that you optimized for is likely to be obsolete. Programmers very often underestimate this time lag.
- Thinking in terms of specific processor models rather than processor features. The programmer typically thinks "what works best on processor X?" rather than "what works best on processors with this instruction set?". A list of which code branch to use for each processor model is going to be very long and difficult to maintain. And it is unlikely that the end user will have an up-to-date version. The CPU dispatcher should not look at CPU brand names and model numbers, but on what instruction sets and other features it has.
- Assuming that processor model numbers form a logical sequence. If you know that processor model N supports a particular instruction set, then you cannot assume that model N+1 supports at least the same instruction set. Neither can you assume that model N-1 is inferior. A model with a higher number is not necessarily newer. The CPU family and model numbers are not always sequential, and you cannot make any assumption about an unknown CPU based on its family and model number.
- Failure to handle unknown processors properly. Many CPU dispatchers are designed to handle only known processors. Other brands or models that were unknown at the time of programming will typically get the generic branch, which is the one that gives the worst possible performance. We must bear in mind, that many users will prefer to run a speed-critical program on the newest CPU model, which quite likely is a model that was unknown at the time of programming. The CPU dispatcher should give a CPU of unknown brand or model the best possible branch if it has an instruction set that is compatible with that branch. The common excuse that "we don't support processor X" is simply not appropriate here. It reveals a funda- mentally flawed approach to CPU dispatching.
- Underestimating the cost of keeping a CPU dispatcher updated. It is tempting to fine-tune the code to a specific CPU model and then think that you can make an update when the next new model comes on the market. But the cost of fine-tuning, testing, verifying and maintaining a new branch of code is so high that it is unrealistic that you can do this every time a new processor enters the market for many years to come. Even big software companies often fail to keep their CPU dispatchers up to date. A more realistic goal is to make a new branch only when a new instruction set opens the possibility for significant improvements.
- Making too many branches. If you are making branches that are fine-tuned for specific CPU brands or specific models then you will soon get a lot of branches that take up cache space and are difficult to maintain. Any specific bottleneck or any particularly slow instruction that you are dealing with in a particular CPU model is likely to be irrelevant within a year or two. Often, it is sufficient to have just two branches: one for the latest instruction set and one that is compatible with CPUs that are up to five or ten years old. The CPU market is developing so fast that what is brand new today will be mainstream next year.
- Ignoring virtualization. The time when the CPUID instruction was certain to truly represent a known CPU model is over. Virtualization is becoming increasingly important. A virtual processor may have a reduced number of cores in order to reserve resources for other virtual processors on the same machine. The virtual processor may be given a false model number to reflect this or for the sake of compatibility with some legacy software. It may even have a false vendor string. In the future we may also see emulated processors and FPGA soft cores that do not correspond to any known hardware CPU. These virtual processors can have any brand name and model number. The only CPUID information that we can surely rely on is the feature information, such as supported instruction sets and cache sizes.
Fortunately, the solution to these problems is quite simple in most cases: The CPU dispatcher should have as few branches as possible, and the dispatching should be based on which instruction sets the CPU supports, rather than its brand, family and model number.
I have seen many examples of poor CPU dispatching. For example, the latest version of Mathcad (v. 15.0) is using a six years old version of Intel's Math Kernel Library (MKL v. 7.2). This library has a CPU dispatcher that doesn't handle current CPUs optimally. The speed for certain tasks on current Intel CPUs can be increased by more than 33% when the CPUID is artificially changed to the old Pentium 4. The reason is that the CPU dispatcher in the MKL relies on the CPU family number, which is 15 on the old Pentium 4, while all newer Intel CPUs have family number 6! The speed on non-Intel CPUs was more than doubled for this task when the CPUID was manipulated to fake an Intel Pentium 4. Even worse, many software products fail to recognize VIA processors because this brand was less popular at the time the software was developed.
A CPU dispatch mechanism that treats different brands of CPUs unequally can become a serious legal issue, as you can read about in my blog. Here, you can also find more examples of bad CPU dispatching.
Obviously, you should apply CPU dispatching only to the most critical part of the program - preferably isolated into a separate function library. The radical solution of making the entire program in multiple versions should be used only when instruction sets are mutually incompatible. A function library with a well-defined functionality and a well-defined interface to the calling program is more manageable and easier to test, maintain and verify than a program where the dispatch branches are scattered everywhere in the source files.
13.2 Model-specific dispatching
There may be cases where a particular code implementation works particularly bad on a particular processor model. You may ignore the problem and assume that the next processor model will work better. If the problem is too important to ignore, then the solution is to make a negative list of processor models on which this code version performs poorly. It is not a good idea to make a positive list of processor models on which a code version performs well. The reason is that a positive list needs to be updated every time a new and better processor appears on the market. Such a list is almost certain to become obsolete within the lifetime of your software. A negative list, on the other hand, does not need updating in the likely case that the next generation of processors is better. Whenever a processor has a particular weakness or bottleneck, it is likely that the producer will try to fix the problem and make the next model work better.
Remember again, that most software runs most of the time on processors that were unknown at the time the software was coded. If the software contains a positive list of which processor models to run the most advanced code version on, then it will run an inferior version on the processors that were unknown at the time it was programmed. But if the software contains a negative list of which processor models to avoid running the advanced version on, then it will run the advanced version on all newer models that were unknown at the time of programming.
13.3 Difficult cases
In most cases, the optimal branch can be chosen based on the CPUID information about supported instruction sets, cache size, etc. There are a few cases, however, where there are different ways of doing the same thing and the CPUID instruction doesn't give the necessary information about which implementation is best. These cases are sometimes dealt with in assembly language. Here are some examples:
- strlen function. The string length function scans a string of bytes to find the first byte of zero. A good implementation uses XMM registers to test 16 bytes at a time and afterwards a BSF (bit scan forward) instruction to localize the first byte of zero within a block of 16 bytes. Some CPUs have particularly slow implementations of this bit scan instruction. Programmers that have tested the strlen function in isolation have been unsatisfied with the performance of this function on CPUs with a slow bit scan instruction and have implemented a separate version for specific CPU models. However, we must consider that the bit scan instruction is executed only once for each function call so that you have to call the function billions of times before the performance even matters, which few programs do. Hence, it is hardly worth the effort to make special versions of the strlen function for CPUs with slow bit scan instructions. My recommendation is to use the bit scan instruction and expect this to be the fastest solution on future CPUs.
- Half size execution units. The size of vector registers has been increased from 64-bit MMX to 128-bit XMM and 256-bit YMM registers. The first processors that supported 128-bit vector registers had in fact only 64-bit execution units. Each 128-bit operation was split into two 64-bit operations so that there was hardly any speed advantage in using the larger vector size. Later models had the full 128-bit execution units and hence higher speed. In the same way, the first processors that supported 256-bit instructions were splitting 256-bit read operations into two 128-bit reads. The same can be expected for the forthcoming 512-bit instruction set and for further expansions of the register size in the future. Typically, the full advantage of a new register size comes only in the second generation of processors that support it. There are situations where a vector implementation is optimal only on CPUs with full-size execution units. The problem is that it is difficult for the CPU dispatcher to know whether the largest vector register size is handled at half speed or full speed. A simple solution to this problem is to use a new register size only when the next higher instruction set is supported. For example, use AVX only when AVX2 is supported in such applications. Alternatively, use a negative list of processors on which it is not advantageous to use the newest instruction set.
- High precision math. Libraries for high precision math allow addition of integers with a very large number of bits. This is usually done in a loop of ADC (add with carry) instructions where the carry bit must be saved from one iteration to the next. The carry bit can be saved either in the carry flag or in a register. If the carry bit is kept in the carry flag then the loop branch must rely on instructions that use the zero flag and don't modify the carry flag (e.g. DEC, JNZ). This solution can incur a large delay due to the so-called partial flags stall on some processors because the CPU has problems separating the flags register into the carry and zero flags on older Intel CPUs, but not on AMD CPUs (See manual 3: "The microarchitecture of Intel, AMD and VIA CPUs"). This is one of the few cases where it makes sense to dispatch by CPU brand. The version that works best on the newest CPU of a particular brand is likely to be the optimal choice for future models of the same brand. Newer processors support the ADX instructions for high precision math.
Memory copying. There are several different ways of copying blocks of memory. These methods are discussed in manual 2: "Optimizing subroutines in assembly language", section 17.9: "Moving blocks of data", where it is also discussed which method is fastest on different processors. In a C++ program, you should choose an up-to-date function library that has a good implementation of the memcpy function. There are so many different cases for different microprocessors, different alignments and different sizes of the data block to copy that the only reasonable solution is to have a standard function library that takes care of the CPU dispatching. This function is so important and generally used that most function libraries have CPU dispatching for this function, though not all libraries have the best and most up-to-date solution. The compiler is likely to use the memcpy function implicitly when copying a large object, unless there is a copy constructor specifying otherwise.
In difficult cases like these, it is important to remember that your code is likely to run most of its time on processors that were unknown at the time it was programmed. Therefore, it is important to consider which method is likely to work best on future processors, and choose this method for all unknown processors that support the necessary instruction set. It is rarely worth the effort to make a CPU dispatcher based on complicated criteria or lists of specific CPU models if the problem is likely to go away in the future due to general improvements in microprocessor hardware design.
The ultimate solution would be to include a performance test that measures the speed of each version of the critical code to see which solution is optimal on the actual processor. However, this involves the problems that the clock frequency may vary dynamically and that measurements are unstable due to interrupts and task switches; so that it is necessary to test the different versions alternatingly several times in order to make a reliable decision.
13.4 Test and maintenance
There are two things to test when software uses CPU dispatching:
- How much you gain in speed by using a particular code version.
- Check that all code versions work correctly.
The speed test should preferably be done on the type of CPU that each particular branch of code is intended for. In other words, you need to test on several different CPUs if you want to optimize for several different CPUs.
On the other hand, it is not necessary to have many different CPUs to verify that all code branches works correctly. A code branch for a low instruction set can still run on a CPU with a higher instruction set. Therefore, you only need a CPU with the highest instruction set in order to test all branches for correctness. It is therefore recommended to put a test feature into the code that allows you to override the CPU dispatching and run any code branch for test purposes.
If the code is implemented as a function library or a separate module then it is convenient to make a test program that can call all code branches separately and test their functionality. This will be very helpful for later maintenance. However, this is not a textbook on test theory. Advice on how to test a software module for correctness must be found elsewhere.
13.5 Implementation
The CPU dispatch mechanism can be implemented in different places making the dispatch decision at different times:
- Dispatch on every call. A branch tree or switch statement leads to the appropriate version of the critical function. The branching is done every time the critical function is called. This has the disadvantage that the branching takes time.
- Dispatch on first call. The function is called through a function pointer which initially points to a dispatcher. The dispatcher changes the function pointer and makes it point to the right version of the function. This has the advantage that it does not spend time on deciding which version to use in case the function is never called. This method is illustrated in example 13.1 below.
- Make pointer at in